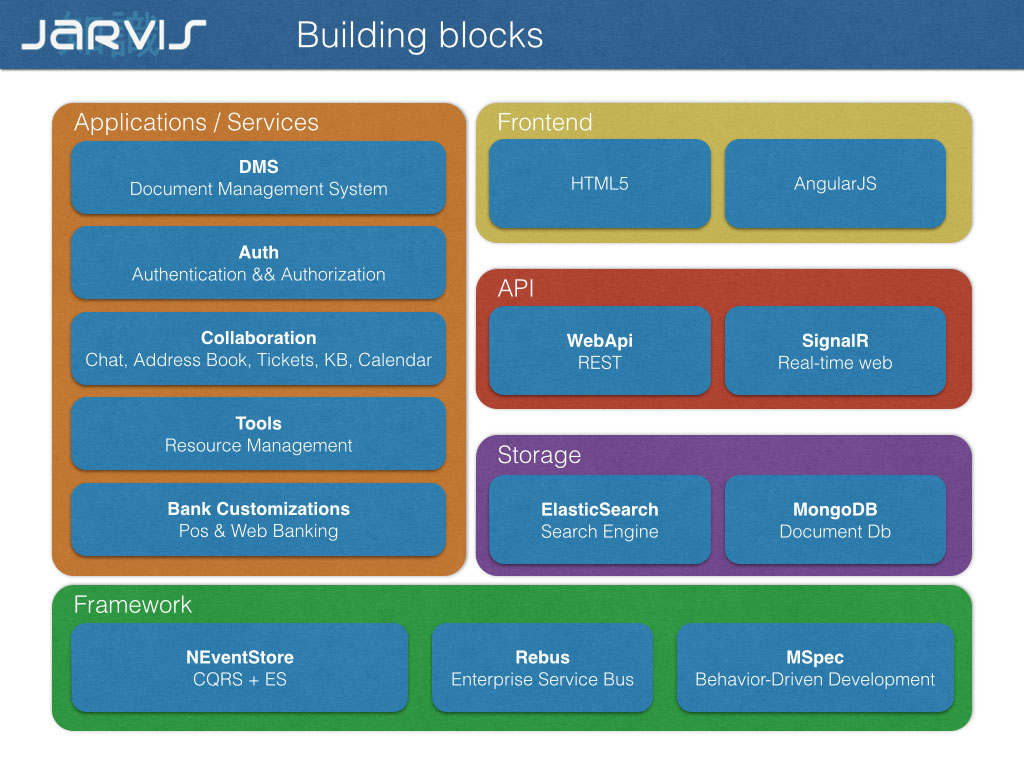
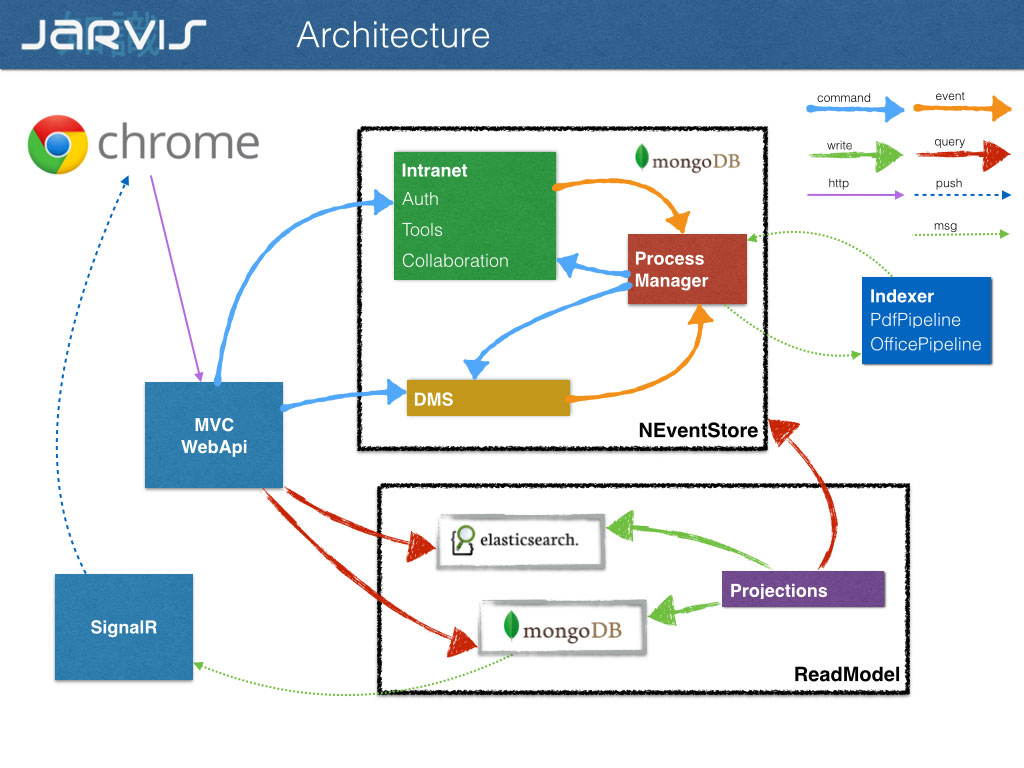
What is
Programmers should speak the language of domain experts to avoid miscommunication, delays, and errors. To avoid mental translation between domain language and code, design your software to use the language of the domain. Reflect in code how users of the software think and speak about their work. One powerful approach is to create a domain model.
The ubiquitous language is a living language. Domain experts influence design and code and the issues discovered while coding influence domain experts. When you discover discrepancies, it's an opportunity for conversation and joint discovery. Then update your design to reflect the results.
Is it all about terms?
Some time ago I had the pleasure to meet with some friends for a GUISA meeting.
Andrea Saltarello gave the “Ubiquitous Language Smackdown” talk in which he shared his experience. We made a very similar experience ourselves (same terms, same communication issues with our customer), but I was firmly convinced that this approach could be used only on projects and was not suitable for products where domain experts are our clients (we craft business software for SME and Public Sector).
Based on our experience every client speaks it’s own language; it can depends on the market, the geographical location (even within the same country) and company size.
Among our products there’s a Manufacturing execution system; if we talk to a mechanical parts manufacturer we can refer to “Bill of Materials”, but if we talk to a fashion manufacturer and we say “Bill of Materials” the games are over: “your product is not for us, we don’t deal with BOM”. Their bill of materials (IT: “distinta base”) is “Scheda tecnica”; I don’t know how to correctly translate it with the correct meaning in english, maybe there’s not this distinction. If we talk with a PCB assembly company, “Scheda tecnica” means “Product Sheet”.
With all these terms referring to the same piece of functionality how can we design and code our model in an Ubiquitous way?
We gave up on UL until…
No, it’s all about Meaning…
One year later I was asked to do a three days class on CQRS+ES, usually I drop these kind of requests because it’s not our business, our goal is to delivery (working) software to our customers; teaching others to do the same is community stuff.
This time I made an exception, and something happened: “Semantic… semantic… semantic…” I found myself talking all the time about domain semantics and how domain semantics can help us to shape our models.
Probably that GUISA talk was the inception, unconsciously we started to use and profit UL in a new way (thanks again Andrea).
The whole thing emerged clearly with Evenstorming.
There's a sign on the wall but she wants to be sure
Cause you know sometimes words have two meanings
Stairway to Heaven - Led Zeppelin
We can’t use Ubiquitous Language with different customers and in our code base
but we can use it on a smaller scope: a single organization.
Within a single organization Ubiquitous Language is an invaluable discovery tool;
Ubiquitous Language exploration has become the cornerstone of our
Evenstorming
process (..more on slideshare).
…and Behaviour.
As expected, when we found that the same term is used by the people in the organization with different meanings we have probably saved many hours of work; I ask the users to write down on a wide blank post-it the meaning of every single term as soon as it materialize in any command / event / readmodel post-it.
The discussion starts and leads us very quickly to domain discovery down at the rainbow’s end!
Yes, that’s the fastest way to get to the “Pot of Gold”: term => meaning => use cases => behavior.
Stay tuned for the next post, I’ll tell you how Ubiquitous Language helped us to discover behaviour and model the “Document” aggregate in our DMS.
(spoiler: it’s not a single Aggregate root)